
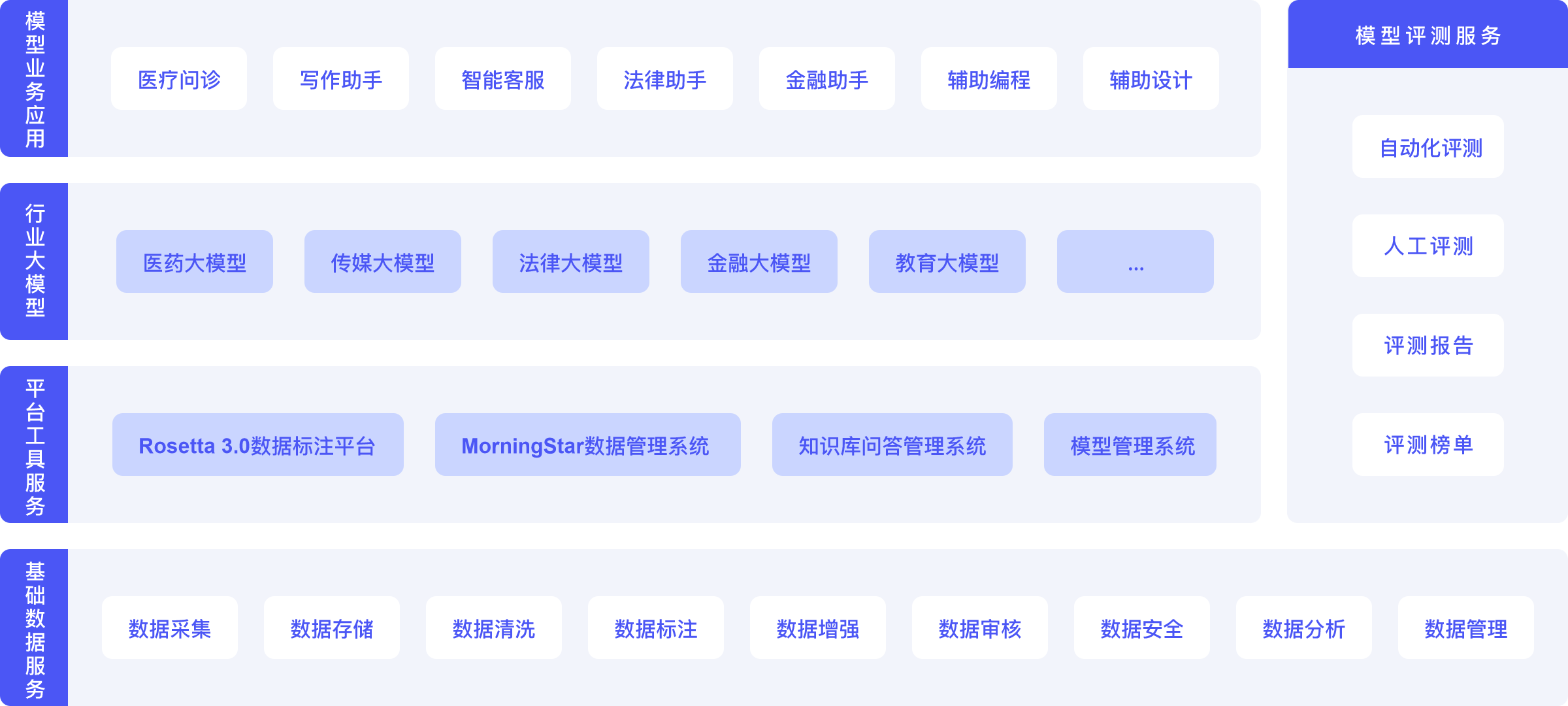
星尘COSMO大模型数据金字塔解决方案






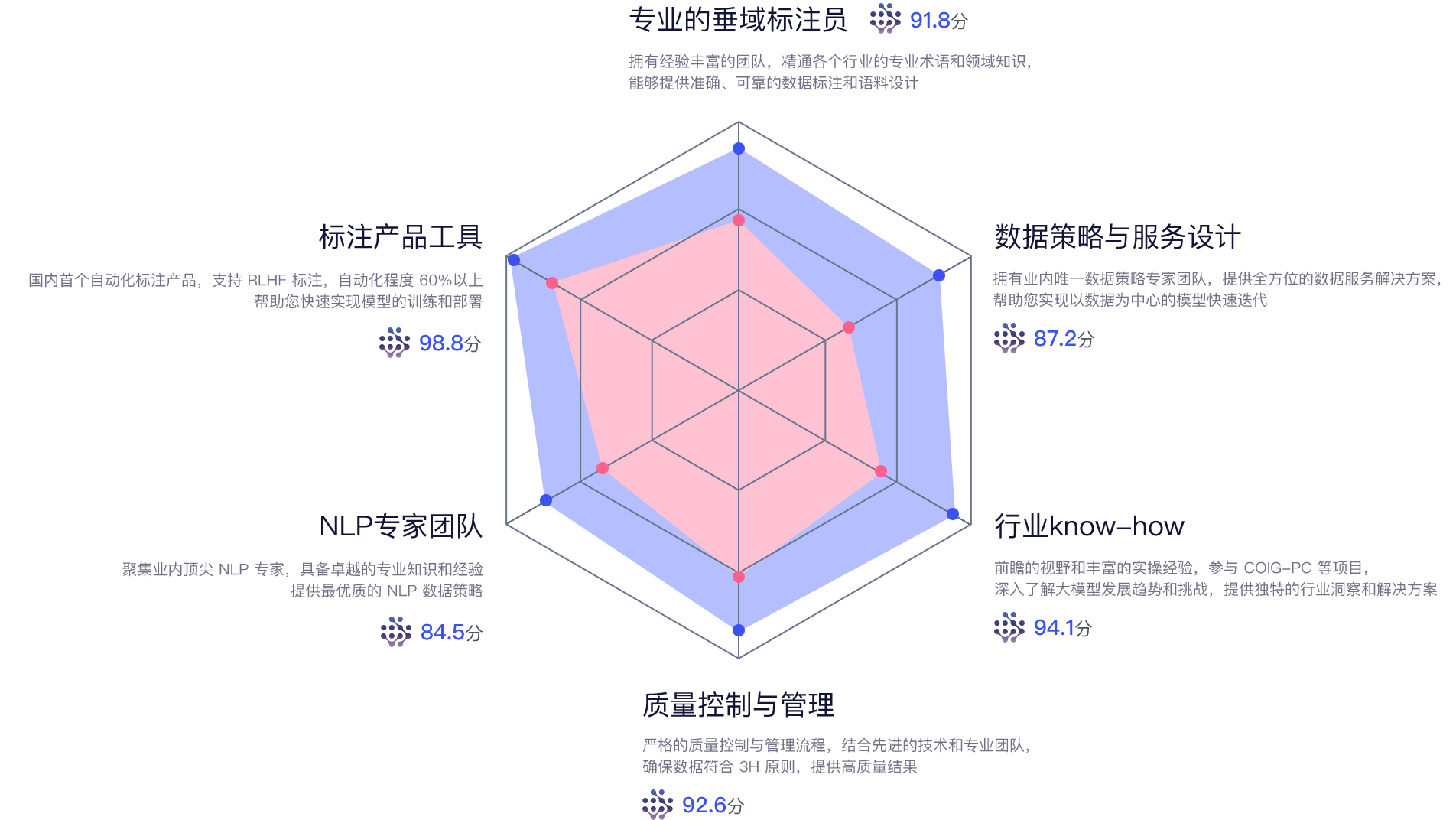

卓越的行业经验
庞大的标注人力网络:汇集了大量优秀的人才,确保提供高质量的数据标注服务。
经验丰富的项目经理:项目经理行业经验丰富,提供专业的项目管理和协调服务。
顶尖客户与前沿项目经验:多家国内知名企业合作,提供最佳实践和解决方案。

强大的专家团队
NLP专家:我们的团队拥有多位自然语言处理领域的顶级专家,为您的AI项目提供专业的技术支持和指导。
数据策略专家:我们的数据策略专家具备丰富的行业知识和经验,能为您提供定制化的数据策略和解决方案。

高效的自动化产品工具
数据处理流程编排:通过对数据处理流程的组织和安排,实现自定义配置工作流程。
算法辅助:实时接入客户算法,支持Chat标注和RLHF人类反馈,确保数据有效地提升模型训练效果。
自动化任务调度:提供自动化的工具,支持Chat标注和Self Instruct,节省成本。

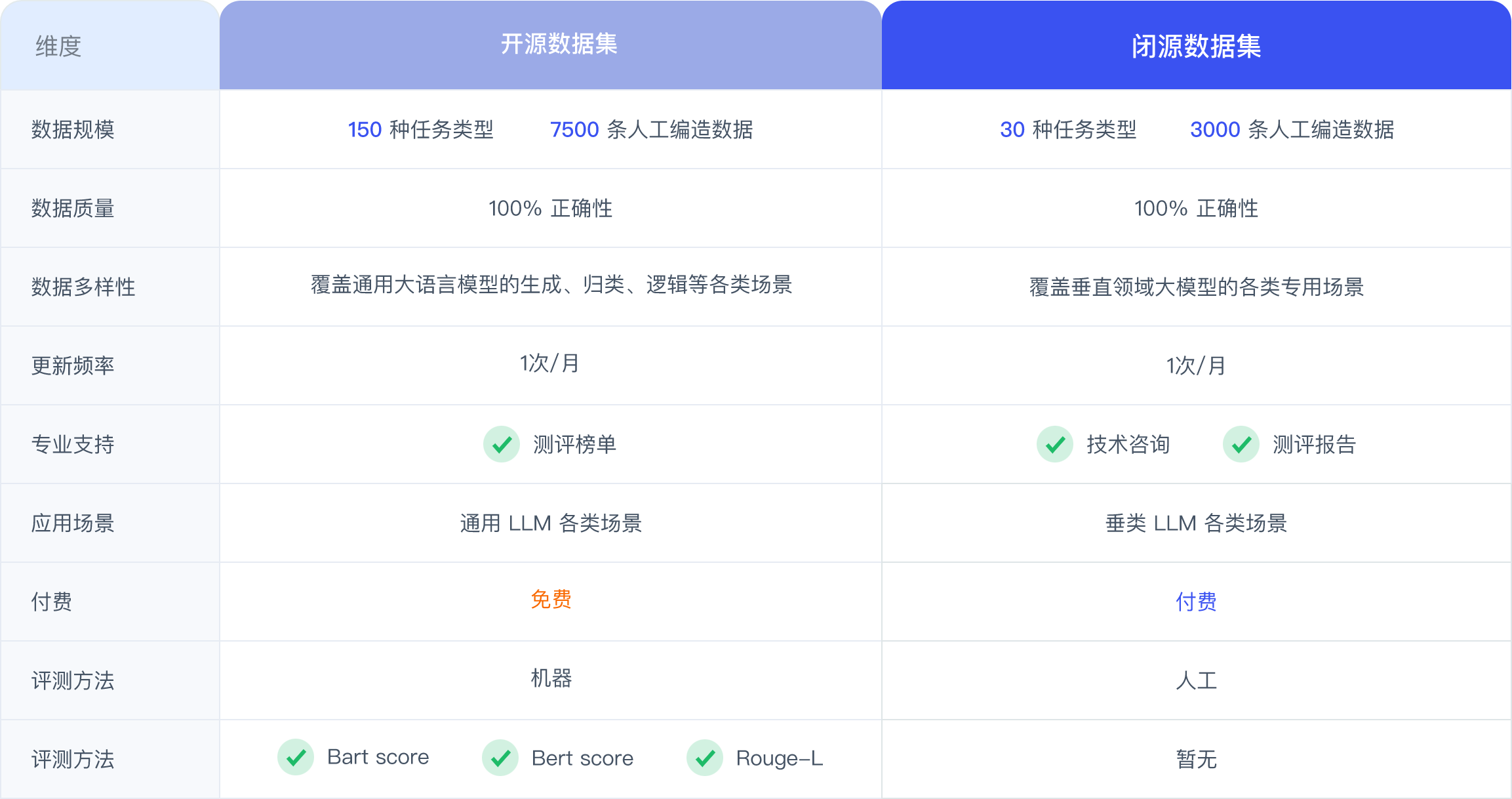
轻松获取
满足您的基本需求
优质数据集
价格实惠
专为您量身打造
满足个性化需求的精准数据集
价值升级
一次性拥有
全方位解锁AI训练潜能
性价比超高
专属定制
为您的业务场景量身定制
高端解决方案
尽享尊贵服务

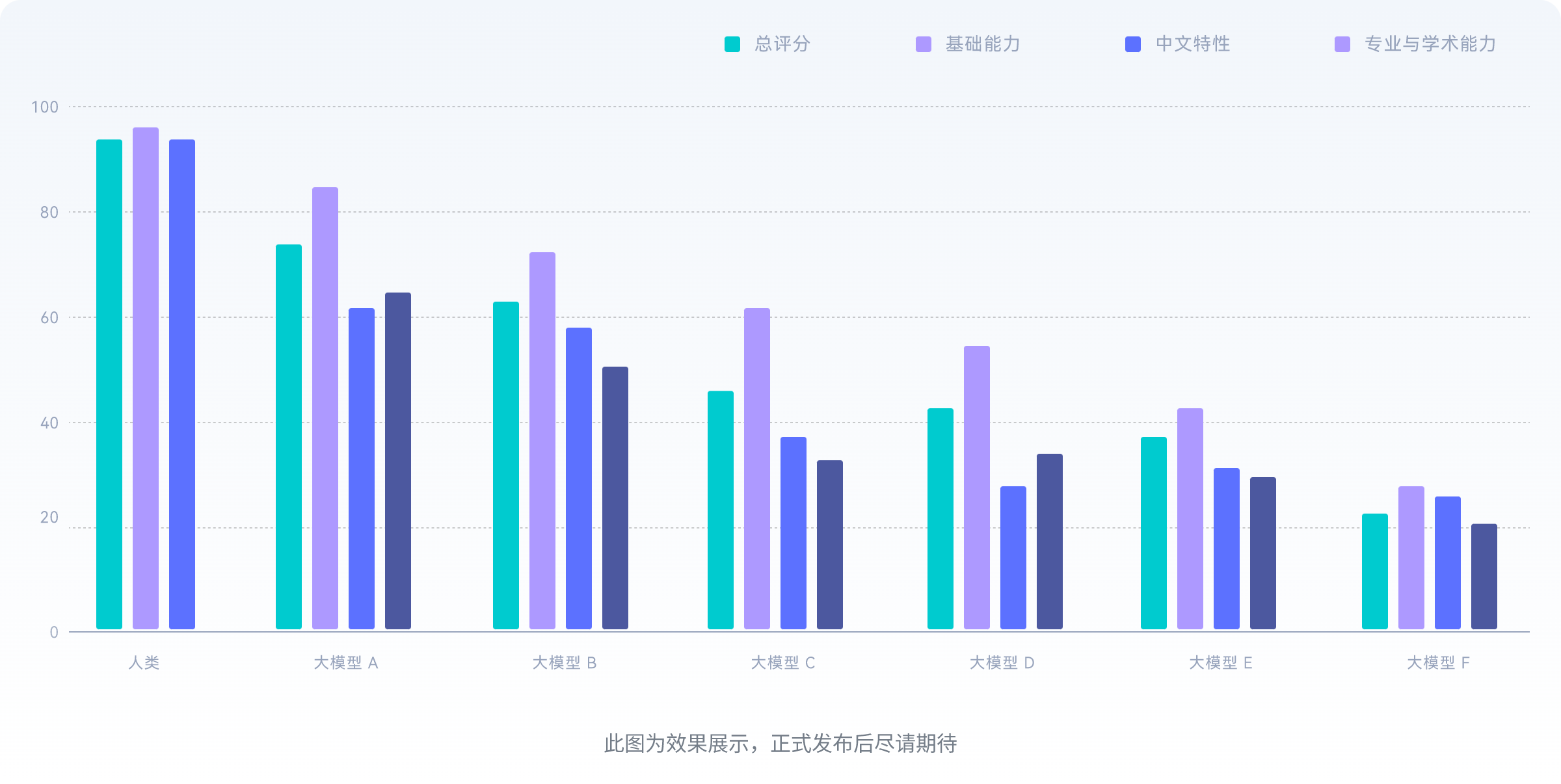

















专业的Benchmark测评报告
我们通过综合评估指标和精心设计的实验,为您呈现了一系列详尽的测评结果,助您全面了解大型语言模型的指令跟随能力。
右侧报告为示意图,闭源测评报告敬请期待!






通用大模型
自然语言处理、文本生成、文本分类、情感分析、智能问答
通用大模型
可应对多种任务和场景,包括自然语言处理、文本生成、文本分类、情感分析、智能问答等多个领域,为各行各业提供智能化解决方案。
医疗大模型
病例分析、诊断建议、药物推荐、医学文献检索、疾病预测、患者健康管理
医疗大模型
可辅助医生进行病例分析、诊断建议、药物推荐等;或应用于医学文献检索、疾病预测、患者健康管理等。

法律大模型
合同审查、法律咨询、案件分析、法规检索
法律大模型
可应用于合同审查、法律咨询、案件分析、法规检索等场景,辅助律师和法务人员高效处理法律事务,提升行业的工作效率。

媒体大模型
新闻撰写、内容策划、社交媒体
媒体大模型
适用于新闻、广告、文学等媒体领域,在新闻撰写、内容策划、社交媒体管理、智能推荐等方面具有广泛应用。
企业万能助理
客户服务、内部沟通、文档管理、市场分析
企业万能助理
针对企业场景进行优化,可应用于客户服务、内部沟通、文档管理、市场分析等多个场景。
更多行业
与您共创
联系我们,获取一对一数据策略服务
我们关注全球最前沿的趋势,拥有宏大的视野和业内最领先的经验,以期为您提供最优质的服务, 为您打造最坚实的数据底座,助您解锁更高效的大模型训练。

© 2024 北京星尘纪元智能科技有限公司 保留所有权